HDclassif: Classification and clustering for high-dimensional data
Description.
We present the HDclassif package which is devoted to the clustering and the discriminant analysis of high-dimensional data. The classification methods proposed in the package result from a new parametrization of the Gaussian mixture model which combines the idea of dimension reduction and model constraints on the covariance matrices. The supervised classification method using this parametrization has been called High Dimensional Discriminant Analysis (HDDA). In a similar manner, the associated clustering method has been called High Dimensional Data Clustering (HDDC) and uses the Expectation-Maximization (EM) algorithm for inference. In order to correctly fit the data, both methods estimate the specific subspace and the intrinsic dimension of the groups. Due to the constraints on the covariance matrices, the number of parameters to estimate is significantly lower than other model-based methods and this allows the methods to be stable and efficient in high-dimensional spaces. Experiments on artificial and real datasets show that HDDC and HDDA perform better than existing classical methods on high-dimensional datasets, even with small datasets
Participants.
- Laurent Bergé (University Bordeaux 4).
Publications.
L. Bergé, C. Bouveyron & S. Girard. "HDclassif: An R package for model-based clustering and discriminant analysis of high-dimensional data, Journal of Statistical Software, 46(6), 1--29, 2012.
[Associated technical report: pdf].
C. Bouveyron, G. Celeux & S. Girard "Intrinsic dimension estimation by maximum likelihood in isotropic probabilistic PCA",
Pattern Recognition Letters, 32(14), 1706--1713, 2011.
[Associated technical report: pdf].
C. Bouveyron & S. Girard. "Classification supervisée et non supervisée des données de grande dimension, La revue Modulad, 40, 81--102, 2009.
C. Bouveyron & S. Girard. "Robust supervised classification with mixture models: Learning from data with uncertain labels",
Pattern Recognition, 42(11), 2649--2658, 2009.
[Associated technical report: pdf].
C. Bouveyron, S. Girard & C. Schmid. "High Dimensional Data Clustering", Computational Statistics and Data Analysis, 52, 502--519, 2007.
[Associated technical report: ps/pdf].
C. Bouveyron, S. Girard & C. Schmid. "High-dimensional discriminant
Analysis", Communication in Statistics - Theory and Methods,
36(14), 2607--2623, 2007.
[Associated technical report (in french):
ps/pdf].
C. Bouveyron, S. Girard & C. Schmid. "Class-specific subspace
discriminant analysis for high-dimensional data", In C. Saunders et
al., editors, Lecture Notes in Computer Science, volume 3940,
p. 139-150. Springer-Verlag, Berlin Heidelberg, 2006.
Download.
- A toolbox for R is available here.
- A toolbox for Matlab is available here.
- The software is now included in MIXMOD (MIXture MODelling), a software for density estimation, clustering or discriminant analysis problems.
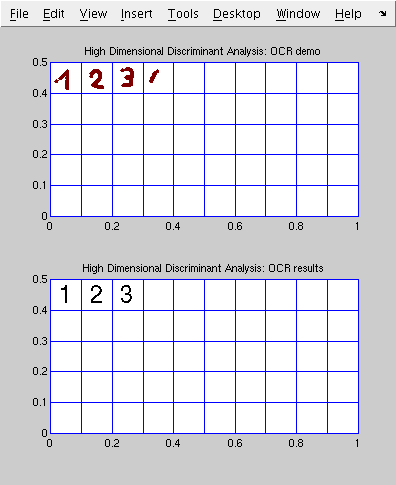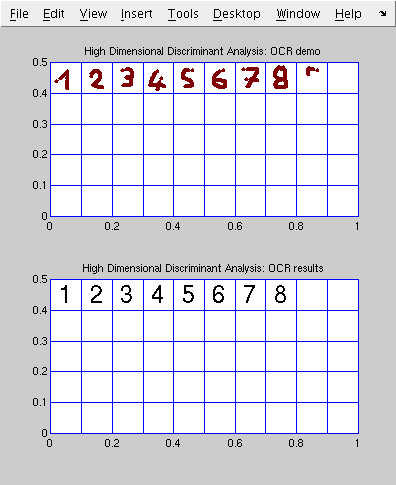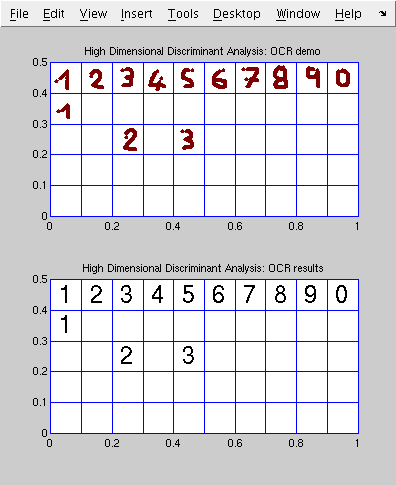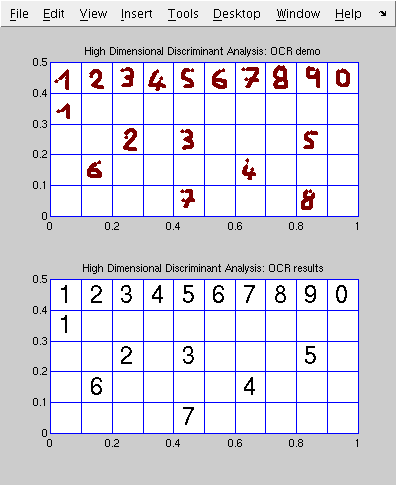
- Here is, a short demonstration of optical character recognition using these methods.