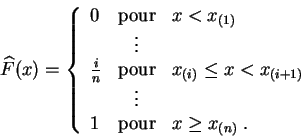La
distribution empirique
associée à un échantillon
est la
distribution de probabilité
sur l'ensemble des modalités qui
affecte chaque
observation du poids ![]() .
.
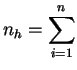 1
1
l'effectif de la valeur ![]() .
La
distribution empirique
de
l'échantillon
est la loi de probabilité
.
La
distribution empirique
de
l'échantillon
est la loi de probabilité
![]() sur l'ensemble
sur l'ensemble
![]() , telle que :
, telle que :
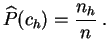
La moyenne, la variance et l'écart-type peuvent être vus comme des caractéristiques de la distribution empirique. La moyenne de l'échantillon est l'espérance de sa distribution empirique. Pour un caractère discret, ou continu regroupé en classes, la valeur modale, ou mode de la distribution empirique est la valeur (ou la classe) qui a la fréquence la plus élevée. Une distribution empirique est dite unimodale si cette fréquence est significativement plus grande que les autres. Elle peut être bimodale ou multimodale dans d'autres cas.
Pour étudier une distribution empirique, la première étape consiste à trier les données par ordre croissant, à savoir écrire ses statistiques d'ordre .
Voici par exemple un échantillon de taille 10 et ses 10 statistiques d'ordre.
En d'autres termes,
![]() est la proportion d'éléments de
l'
échantillon
qui sont inférieurs ou égaux à
est la proportion d'éléments de
l'
échantillon
qui sont inférieurs ou égaux à ![]() .
Représenter la
fonction de répartition empirique
(en général on
trace seulement les points de coordonnées
.
Représenter la
fonction de répartition empirique
(en général on
trace seulement les points de coordonnées
![]() , donne
une idée de la
distribution empirique.
, donne
une idée de la
distribution empirique.
Dans le cas où
l'échantillon
est discret (le nombre de valeurs
différentes
![]() est faible devant la taille de
l'échantillon
est faible devant la taille de
l'échantillon
![]() ), on représentera la
distribution empirique
par un
diagramme en bâtons
. Il consiste
à représenter les valeurs différentes
), on représentera la
distribution empirique
par un
diagramme en bâtons
. Il consiste
à représenter les valeurs différentes
![]() en
abscisse, avec au-dessus de chacune une barre verticale de longueur
égale à sa
fréquence expérimentale
en
abscisse, avec au-dessus de chacune une barre verticale de longueur
égale à sa
fréquence expérimentale
![]() . Dans le cas où le nombre
de valeurs différentes est très faible (inférieur à 10), et surtout
pour des
échantillons
qualitatifs, on utilise aussi des représentations
en camembert (pie-chart), ou en barre. Elles consistent à diviser un disque
ou un rectangle proportionnellement aux différentes
fréquences.
. Dans le cas où le nombre
de valeurs différentes est très faible (inférieur à 10), et surtout
pour des
échantillons
qualitatifs, on utilise aussi des représentations
en camembert (pie-chart), ou en barre. Elles consistent à diviser un disque
ou un rectangle proportionnellement aux différentes
fréquences.
La représentation correspondant au
diagramme en bâtons
pour un échantillon
considéré comme continu (lorsque presque toutes les valeurs sont
différentes), est
l'histogramme.
Il suppose que l'on a choisi un nombre de
classes ![]() et un intervalle de représentation
et un intervalle de représentation ![]() , que l'on a
découpé en
, que l'on a
découpé en ![]() intervalles
intervalles
![]() .
On remplace alors la
distribution empirique
par une nouvelle
loi de probabilité,
qui pour tout
.
On remplace alors la
distribution empirique
par une nouvelle
loi de probabilité,
qui pour tout
![]() , charge l'intervalle
, charge l'intervalle
![]() avec sa
fréquence expérimentale
avec sa
fréquence expérimentale
![]() :
:
![$\displaystyle \widehat{P}(]a_{h-1},a_h]) = \frac{1}{n} \sum_{i=1}^n$](img92.gif) 1
1
Tracer un
histogramme
consiste à représenter les classes en
abscisses,
avec au dessus de la ![]() -ième un rectangle de hauteur
-ième un rectangle de hauteur
![]() ,
donc de surface égale à
,
donc de surface égale à ![]() . Cette représentation est celle
d'une
densité de probabilité,
constante sur
chacune des classes. Représenter un
histogramme
implique un certain a priori
sur les
données.
On décide en effet que la
fréquence
de chacune des
classes est bien sa
fréquence empirique
dans
l'échantillon,
mais que la
distribution des
données
à l'intérieur de chaque intervalle est
aléatoire,
de
loi uniforme
sur cet intervalle.
. Cette représentation est celle
d'une
densité de probabilité,
constante sur
chacune des classes. Représenter un
histogramme
implique un certain a priori
sur les
données.
On décide en effet que la
fréquence
de chacune des
classes est bien sa
fréquence empirique
dans
l'échantillon,
mais que la
distribution des
données
à l'intérieur de chaque intervalle est
aléatoire,
de
loi uniforme
sur cet intervalle.