La
modélisation
probabiliste en statistique
consiste à supposer
qu'un
échantillon
observé
![]() est une réalisation
d'un
échantillon
théorique d'une certaine loi de probabilité
est une réalisation
d'un
échantillon
théorique d'une certaine loi de probabilité
![]() , où le paramètre
, où le paramètre ![]() est inconnu. Si tel était
le cas, la
distribution empirique
est inconnu. Si tel était
le cas, la
distribution empirique
![]() de l'échantillon
observé devrait être proche de
de l'échantillon
observé devrait être proche de ![]() . La distribution empirique
d'un
échantillon
est la
loi de probabilité
sur l'ensemble des valeurs,
qui affecte chaque
individu
du poids
. La distribution empirique
d'un
échantillon
est la
loi de probabilité
sur l'ensemble des valeurs,
qui affecte chaque
individu
du poids ![]() .
.
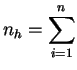 1
1
le nombre de fois où la valeur ![]() a été observée.
La
distribution empirique
de
l'échantillon
est la loi de probabilité
a été observée.
La
distribution empirique
de
l'échantillon
est la loi de probabilité
![]() sur l'ensemble
sur l'ensemble
![]() , telle que :
, telle que :
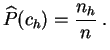
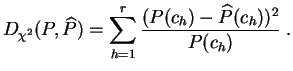
La
distance de Kolmogorov-Smirnov
est la distance de la norme uniforme
entre fonctions de répartitions. Rappelons que la
fonction de répartition
empirique de
l'échantillon
![]() est la fonction de
répartition de sa
distribution empirique.
C'est la fonction en escalier
est la fonction de
répartition de sa
distribution empirique.
C'est la fonction en escalier
![]() qui vaut 0 avant
qui vaut 0 avant ![]() ,
, ![]() entre
entre ![]() et
et ![]() ,
et 1 après
,
et 1 après ![]() (les
(les ![]() sont les
statistiques d'ordre,
c'est-à-dire les valeurs ordonnées de l'échantillon).
sont les
statistiques d'ordre,
c'est-à-dire les valeurs ordonnées de l'échantillon).
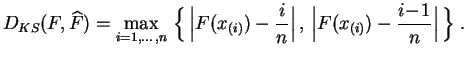
Etant donnés un
échantillon
et une famille de
lois de probabilité
![]() , dépendant du paramètre inconnu
, dépendant du paramètre inconnu ![]() , il est naturel
de choisir comme
modèle
celle des lois de la famille qui s'ajuste le
mieux aux
données.
Cela revient à donner comme
estimation
de
, il est naturel
de choisir comme
modèle
celle des lois de la famille qui s'ajuste le
mieux aux
données.
Cela revient à donner comme
estimation
de ![]() celle pour laquelle la distance entre la loi théorique
celle pour laquelle la distance entre la loi théorique ![]() et la
distribution empirique
de
l'échantillon
est la plus faible.
et la
distribution empirique
de
l'échantillon
est la plus faible.
Considérons par exemple un
échantillon
de
données
binaires. Notons
![]() la
fréquence empirique
des 1. La
distance du chi-deux
entre
la
loi de Bernoulli
de paramètre
la
fréquence empirique
des 1. La
distance du chi-deux
entre
la
loi de Bernoulli
de paramètre ![]() et la distribution empirique
est :
et la distribution empirique
est :
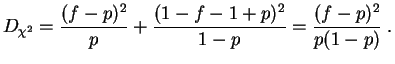
Cette distance est évidemment minimale pour ![]() . Ceci s'étend
trivialement à un nombre fini quelconque d'éventualités : la
loi de probabilité
qui ajuste le mieux une distribution empirique
sur
. Ceci s'étend
trivialement à un nombre fini quelconque d'éventualités : la
loi de probabilité
qui ajuste le mieux une distribution empirique
sur
![]() au sens de la
distance du chi-deux
est celle
qui charge chaque valeur
au sens de la
distance du chi-deux
est celle
qui charge chaque valeur ![]() avec une
probabilité
égale
à la
fréquence expérimentale
de cette valeur.
avec une
probabilité
égale
à la
fréquence expérimentale
de cette valeur.
En pratique, il est rare que l'on puisse ainsi calculer explicitement l'estimation d'un paramètre par ajustement. On doit alors procéder à une minimisation numérique sur le paramètre inconnu.