Le principe de la régression au sens des
moindres carrés,
tel qu'il a
été décrit au paragraphe précédent, est très général.
Etant donné un
caractère
![]() "à expliquer" et des caractères
"à expliquer" et des caractères
![]() "explicatifs", mesurés sur une même
population
de taille
"explicatifs", mesurés sur une même
population
de taille ![]() , on cherche à isoler dans une famille de fonctions
à plusieurs paramètres, une fonction
, on cherche à isoler dans une famille de fonctions
à plusieurs paramètres, une fonction ![]() qui "explique"
qui "explique" ![]() par la
relation :
par la
relation :
Comme critère de choix, on minimise sur toutes les fonctions de la famille l'erreur quadratique définie par :
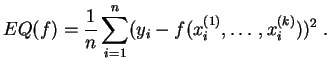
Dans certains cas classiques, on sait résoudre explicitement ce problème de minimisation, et la solution est implémentée dans les environnements de calculs statistiques. C'est le cas pour les exemples que nous donnons ci-dessous. Quand une résolution explicite est impossible, on a recours à des algorithmes de minimisation, comme l'algorithme du gradient.
C'est la généralisation directe de la
régression linéaire simple
du paragraphe précédent. Les fonctions ![]() sont affines :
sont affines :
L'erreur quadratique
à minimiser est une fonction des ![]() paramètres
inconnus
paramètres
inconnus
![]() .
.
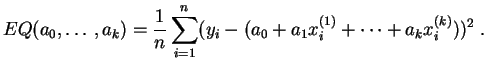
On peut toujours faire passer un hyperplan par ![]() points dans un espace de
dimension
points dans un espace de
dimension ![]() . Si la taille
. Si la taille ![]() de la
population
est inférieure ou
égale à
de la
population
est inférieure ou
égale à ![]() ,
l'erreur quadratique
minimale est donc 0. En pratique,
la régression ne pourra être significative que si
,
l'erreur quadratique
minimale est donc 0. En pratique,
la régression ne pourra être significative que si ![]() est beaucoup plus
grand que
est beaucoup plus
grand que ![]() .
.
Régression polynomiale
simple.
On peut la voir comme une autre généralisation de la
régression linéaire simple,
ou comme un cas particulier de
Régression linéaire multiple.
Un seul
caractère, ![]() , est explicatif. Les fonctions
, est explicatif. Les fonctions ![]() sont
les polynômes de degré
sont
les polynômes de degré ![]() .
.
On peut considérer que les
caractères
![]() sont explicatifs pour
se ramener au cas précédent. Les familles des polynômes
de degrés successifs sont emboîtées. Pour un même ensemble de
données,
l'erreur quadratique
diminuera donc si on augmente
sont explicatifs pour
se ramener au cas précédent. Les familles des polynômes
de degrés successifs sont emboîtées. Pour un même ensemble de
données,
l'erreur quadratique
diminuera donc si on augmente ![]() , pour
s'annuler quand
, pour
s'annuler quand ![]() dépasse
dépasse ![]() . Mais si
. Mais si ![]() est trop grand, la
régression ne sera pas significative. En pratique, il est rare qu'une
régression polynomiale
aille au-delà du degré 3.
est trop grand, la
régression ne sera pas significative. En pratique, il est rare qu'une
régression polynomiale
aille au-delà du degré 3.
Régression polynomiale
multiple.
Quand plusieurs
caractères
sont explicatifs, on peut encore effectuer une
régression sur une famille
de polynômes en les différents
caractères,
de degré fixé. Les termes
faisant intervenir des produits du type
![]() seront
interprétés comme des termes d'interaction entre les caractères
explicatifs. En pratique, on se limite à des polynômes de degré
1 ou 2. Voici pour deux
caractères
explicatifs
seront
interprétés comme des termes d'interaction entre les caractères
explicatifs. En pratique, on se limite à des polynômes de degré
1 ou 2. Voici pour deux
caractères
explicatifs ![]() et
et ![]() ,
les
modèles
les plus fréquemment utilisés.
,
les
modèles
les plus fréquemment utilisés.