La définition 1.4 du paragraphe
précédent fait apparaître le
seuil
comme la
probabilité
![]() ,
fixée a priori, que le
test
rejette
l'hypothèse
,
fixée a priori, que le
test
rejette
l'hypothèse
![]() à
tort.
à
tort.
Une fois les
données
recueillies, la valeur prise par la
statistique de test
sera calculée, et la réponse sera binaire : rejet ou non de
![]() . On préfère souvent garder l'information contenue dans la
valeur de la
statistique de test,
en retournant le
seuil
limite
auquel
. On préfère souvent garder l'information contenue dans la
valeur de la
statistique de test,
en retournant le
seuil
limite
auquel
![]() aurait été rejetée, compte tenu de l'observation.
aurait été rejetée, compte tenu de l'observation.
Prenons l'exemple (fréquent) d'une
hypothèse
![]() sous laquelle
la
statistique de test
sous laquelle
la
statistique de test
![]() suit la
loi normale
suit la
loi normale
![]() . La règle
de rejet pour le
test
bilatéral
de
seuil
0.05 est :
. La règle
de rejet pour le
test
bilatéral
de
seuil
0.05 est :
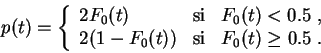
Cependant calculer une
p-valeur
pour un
test
bilatéral
est assez artificiel.
Au vu de la valeur prise par ![]() , on aura tendance à effectuer plutôt
un
test
unilatéral
visant à décider si la valeur observée est
trop grande ou trop petite. Pour une
statistique de test
suivant la loi
, on aura tendance à effectuer plutôt
un
test
unilatéral
visant à décider si la valeur observée est
trop grande ou trop petite. Pour une
statistique de test
suivant la loi
![]() , la valeur 2.72 est clairement à droite de la
distribution. Le problème ne se pose plus de savoir si elle est trop petite,
mais plutôt si elle est significativement trop grande. En pratique,
pour une
statistique de test
de
fonction de répartition
, la valeur 2.72 est clairement à droite de la
distribution. Le problème ne se pose plus de savoir si elle est trop petite,
mais plutôt si elle est significativement trop grande. En pratique,
pour une
statistique de test
de
fonction de répartition
![]() sous
sous
![]() , on définira souvent la
p-valeur
de la valeur
, on définira souvent la
p-valeur
de la valeur ![]() par :
par :
La connaissance de la
p-valeur
rend inutile le calcul préalable de
la région de rejet : si ![]() est la
p-valeur
d'une observation
est la
p-valeur
d'une observation ![]() sous
l'hypothèse
sous
l'hypothèse
![]() , on obtient un
test
de
seuil
, on obtient un
test
de
seuil
![]() par la
règle de rejet :
par la
règle de rejet :
Quand la
statistique de test
est discrète, il faut inclure la valeur
observée dans l'intervalle dont on calcule
la
probabilité.
Pour un
test
unilatéral
à gauche, cela n'induit
pas de changement : ![]() est la probabilité
que
est la probabilité
que ![]() soit inférieure ou égale à
soit inférieure ou égale à ![]() . Pour un
test
unilatéral
à droite sur une variable à valeurs dans
. Pour un
test
unilatéral
à droite sur une variable à valeurs dans
![]() (le cas le plus fréquent)
il faudra calculer
(le cas le plus fréquent)
il faudra calculer
![]() . Supposons par exemple que la
loi de
. Supposons par exemple que la
loi de ![]() soit la
loi binomiale
soit la
loi binomiale
![]() , la p-valeur
de 60 est la
probabilité
que
, la p-valeur
de 60 est la
probabilité
que ![]() soit supérieure ou égale
à 60, à savoir :
soit supérieure ou égale
à 60, à savoir :