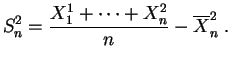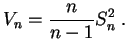Dans cette section, nous illustrons les notions d'estimateur, de convergence et de biais sur trois exemples, l'estimation d'une variance, le problème des questions confidentielles, et les comptages par capture-recapture.
Estimateurs de la variance.
Soit
![]() un
échantillon
d'une loi inconnue
un
échantillon
d'une loi inconnue ![]() , qui sera
supposée admettre des moments de tous ordres. Nous
avons vu que la
moyenne empirique
, qui sera
supposée admettre des moments de tous ordres. Nous
avons vu que la
moyenne empirique
![]() est un
estimateur convergent
de
l'espérance.
C'est un
estimateur sans biais,
et sa
variance
est égale à la
variance
de la loi
est un
estimateur convergent
de
l'espérance.
C'est un
estimateur sans biais,
et sa
variance
est égale à la
variance
de la loi ![]() , divisée par
, divisée par
![]() . Comment estimer la
variance
de
. Comment estimer la
variance
de ![]() ?
L'estimateur
le plus naturel
est le suivant.
?
L'estimateur
le plus naturel
est le suivant.
Si
![$\displaystyle \mathbb{E}[S^2_n] = \frac{n-1}{n}Var[X]\;.
$](img111.gif)
Démonstration : Calculons tout d'abord
![]() .
.
![\begin{displaymath}
\begin{array}{ccc}
\mathbb{E}[\overline{X}_n^2]&=&\frac{1}{n...
...X_i^2 + \sum_{i=1}^n\sum_{j\neq i} X_iX_j\right]\;.
\end{array}\end{displaymath}](img113.gif)
Par définition d'un
échantillon,
![]() sont
indépendantes
et de même loi. Donc
sont
indépendantes
et de même loi. Donc
![]() et
et
![]() .
En reportant ces valeurs on obtient :
.
En reportant ces valeurs on obtient :
![\begin{displaymath}
\begin{array}{ccc}
\mathbb{E}[\overline{X}^2_n]&=&\frac{1}{n...
...mathbb{E}[X^2] + \frac{n-1}{n} (\mathbb{E}[X])^2\;.
\end{array}\end{displaymath}](img117.gif)
On a donc :
![\begin{displaymath}\begin{array}{ccc}
\mathbb{E}[S^2_n]&=&\frac{1}{n}\mathbb{E}[...
...} (\mathbb{E}[X])^2)\\
&=&\frac{n-1}{n}Var[X]\;.
\end{array}\end{displaymath}](img118.gif)
![]()
Pour transformer ![]() en un
estimateur
non
biaisé,
il suffit de corriger
le
biais
par un facteur multiplicatif.
en un
estimateur
non
biaisé,
il suffit de corriger
le
biais
par un facteur multiplicatif.
On peut estimer
l'écart-type
par
![]() ou bien
ou bien
![]() . Notons
qu'en général aussi bien
. Notons
qu'en général aussi bien
![]() que
que
![]() sont des
estimateurs
biaisés
de
sont des
estimateurs
biaisés
de
![]() .
La différence entre les deux
estimateurs
tend vers
0 quand la taille
.
La différence entre les deux
estimateurs
tend vers
0 quand la taille ![]() de
l'échantillon
tend vers l'infini. Néanmoins,
la plupart des calculatrices proposent les deux
estimateurs
de
l'écart-type
(touches
de
l'échantillon
tend vers l'infini. Néanmoins,
la plupart des calculatrices proposent les deux
estimateurs
de
l'écart-type
(touches ![]() et
et
![]() ). Certains logiciels
(en particulier Scilab) calculent par défaut la valeur de
). Certains logiciels
(en particulier Scilab) calculent par défaut la valeur de ![]() ou
ou
![]() , d'autres
, d'autres ![]() ou
ou
![]() . Dans la suite, nous
utiliserons surtout
. Dans la suite, nous
utiliserons surtout ![]() , malgré l'inconvénient du
biais.
, malgré l'inconvénient du
biais.
Questions confidentielles.
Certains sujets abordés dans les enquêtes d'opinion sont parfois
assez intimes, et on court le risque que les personnes interrogées
se refusent à répondre franchement à l'enquêteur, faussant ainsi le
résultat. On peut alors avoir recours à une astuce consistant à
inverser aléatoirement les réponses . Considérons une question
confidentielle pour laquelle on veut estimer la
probabilité
![]() de
réponses positives. L'enquêteur demande à chaque personne interrogée
de lancer un dé. Si le
dé tombe sur
de
réponses positives. L'enquêteur demande à chaque personne interrogée
de lancer un dé. Si le
dé tombe sur ![]() , la personne doit
donner sa réponse sans mentir, sinon elle doit donner l'opinion contraire
à la sienne. Si l'enquêteur ignore le résultat du dé, il ne pourra
pas savoir si la réponse est franche ou non, et on peut espérer
que la personne sondée acceptera de jouer le jeu. Généralisons
légèrement la situation en tirant pour chaque personne une variable
de
Bernoulli
de paramètre
, la personne doit
donner sa réponse sans mentir, sinon elle doit donner l'opinion contraire
à la sienne. Si l'enquêteur ignore le résultat du dé, il ne pourra
pas savoir si la réponse est franche ou non, et on peut espérer
que la personne sondée acceptera de jouer le jeu. Généralisons
légèrement la situation en tirant pour chaque personne une variable
de
Bernoulli
de paramètre ![]() . Si le résultat de cette variable
est 1, la réponse est franche, sinon, elle est inversée.
Soit
. Si le résultat de cette variable
est 1, la réponse est franche, sinon, elle est inversée.
Soit ![]() le nombre de personnes interrogées.
L'enquêteur ne recueille que la
fréquence empirique
le nombre de personnes interrogées.
L'enquêteur ne recueille que la
fréquence empirique
![]() des ``oui''.
La proportion inconnue des ``oui'' à l'issue de la procédure est
des ``oui''.
La proportion inconnue des ``oui'' à l'issue de la procédure est
![]() , et la
fréquence
, et la
fréquence
![]() observée
par l'enquêteur est un
estimateur sans biais
et convergent de
observée
par l'enquêteur est un
estimateur sans biais
et convergent de ![]() .
Remarquons que si
.
Remarquons que si
![]() ,
, ![]() vaut 1/2 quel
que soit
vaut 1/2 quel
que soit ![]() . Mais si
. Mais si
![]() 1/2, on peut exprimer
1/2, on peut exprimer ![]() en fonction
de
en fonction
de ![]() :
:
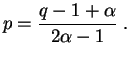
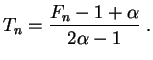
L'espérance
de ![]() est
est ![]() .
La
variance
de
.
La
variance
de ![]() vaut :
vaut :
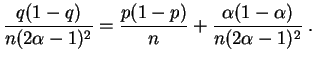
L'estimateur
![]() est sans
biais, sa
variance
tend vers 0, il
est donc convergent.
est sans
biais, sa
variance
tend vers 0, il
est donc convergent.
Pour ![]() fixé,
la
variance
de
fixé,
la
variance
de ![]() tend vers l'infini quand
tend vers l'infini quand ![]() tend vers 1/2.
Elle est minimale si
tend vers 1/2.
Elle est minimale si ![]() 0 ou 1 (mais alors la procédure
perd tout son intérêt). Le problème est donc de choisir
une valeur de
0 ou 1 (mais alors la procédure
perd tout son intérêt). Le problème est donc de choisir
une valeur de ![]() qui soit assez grande pour que la confidentialité
soit crédible, mais suffisamment éloignée de 1/2 pour ne pas
trop augmenter la
variance
de l'estimateur.
Pour le dé, la
valeur de
qui soit assez grande pour que la confidentialité
soit crédible, mais suffisamment éloignée de 1/2 pour ne pas
trop augmenter la
variance
de l'estimateur.
Pour le dé, la
valeur de ![]() est 1/6 et le terme additionnel de la variance
est proportionnel à
est 1/6 et le terme additionnel de la variance
est proportionnel à
![]() 0.3125.
0.3125.
Comptages par capture-recapture
Comment estimer le nombre d'espèces d'insectes vivant sur la terre,
alors que de nombreuses espèces sont encore inconnues ? Comment
connaît-on la
population
de baleines dans les océans ? Le comptage
par capture-recapture permet d'évaluer des tailles de
population
pour
lesquelles un recensement exhaustif est impossible. La méthode est basée
sur une idée simple. Considérons une
population, de taille ![]() inconnue.
On prélève dans un premier temps un
groupe d'individus, de taille
inconnue.
On prélève dans un premier temps un
groupe d'individus, de taille ![]() fixée. Ces individus sont
recensés et marqués de façon à être reconnus ultérieurement.
Plus tard,
on prélève un nouveau groupe de taille
fixée. Ces individus sont
recensés et marqués de façon à être reconnus ultérieurement.
Plus tard,
on prélève un nouveau groupe de taille ![]() , et on observe
le nombre
, et on observe
le nombre ![]() d'individus marqués dans ce nouveau groupe. Si
le deuxième prélèvement est indépendant du premier, la loi
de
d'individus marqués dans ce nouveau groupe. Si
le deuxième prélèvement est indépendant du premier, la loi
de ![]() est la
loi hypergéométrique
de paramètres
est la
loi hypergéométrique
de paramètres ![]() ,
, ![]() et
et ![]() ,
d'espérance
,
d'espérance
![]() . On peut s'attendre à ce que la proportion
. On peut s'attendre à ce que la proportion ![]() d'individus marqués dans le deuxième
échantillon
soit
proche de la proportion d'individus marqués dans l'ensemble de la
population,
d'individus marqués dans le deuxième
échantillon
soit
proche de la proportion d'individus marqués dans l'ensemble de la
population, ![]() . Il est donc raisonnable de proposer comme estimateur
de
. Il est donc raisonnable de proposer comme estimateur
de ![]() la quantité suivante :
la quantité suivante :
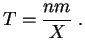
L'inconvénient de cet
estimateur
est qu'il n'est pas défini
si ![]() prend la valeur 0, ce qui arrive avec une
probabilité
strictement
positive. On peut corriger ce défaut de deux manières. La première
consiste à remplacer
prend la valeur 0, ce qui arrive avec une
probabilité
strictement
positive. On peut corriger ce défaut de deux manières. La première
consiste à remplacer ![]() par
par ![]() , ce qui ne devrait pas fausser trop
le résultat si les nombres envisagés sont assez grands. Posons donc :
, ce qui ne devrait pas fausser trop
le résultat si les nombres envisagés sont assez grands. Posons donc :
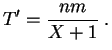
La seconde manière consiste à décider de rejeter a priori les
échantillons
pour lesquels on n'obtiendrait pas
d'individu
marqué.
Ceci revient à remplacer ![]() par une autre
variable aléatoire
par une autre
variable aléatoire
![]() dont la loi est la loi conditionnelle de
dont la loi est la loi conditionnelle de ![]() sachant que
sachant que ![]() est strictement
positif. Posons donc
est strictement
positif. Posons donc
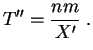
Les deux
estimateurs
sont
biaisés,
le premier a tendance à sous-estimer
![]() , le deuxième à le sur-estimer.
L'écart-type
augmente plus rapidement
que
, le deuxième à le sur-estimer.
L'écart-type
augmente plus rapidement
que ![]() . Il est naturel que la précision relative soit d'autant plus
faible que les
échantillons
recueillis sont petits devant la taille
inconnue de la population.
. Il est naturel que la précision relative soit d'autant plus
faible que les
échantillons
recueillis sont petits devant la taille
inconnue de la population.