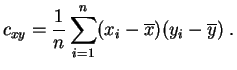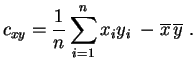Si deux
caractères
quantitatifs ![]() et
et ![]() sont mesurés sur
sont mesurés sur ![]() individus, on peut considérer
l'échantillon bidimensionnel
comme un
nuage
de
individus, on peut considérer
l'échantillon bidimensionnel
comme un
nuage
de ![]() points dans
points dans
![]() . Différentes
caractéristiques
statistiques
permettent de
résumer l'information contenue dans sa forme. Si
. Différentes
caractéristiques
statistiques
permettent de
résumer l'information contenue dans sa forme. Si
![]() et
et
![]() désignent les
moyennes empiriques
des deux
caractères,
le point
désignent les
moyennes empiriques
des deux
caractères,
le point
![]() est le centre de gravité du nuage.
Les
variances empiriques
est le centre de gravité du nuage.
Les
variances empiriques
![]() et
et ![]() traduisent la dispersion des abscisses
et des ordonnées. Pour aller plus loin dans la description, il faut calculer
la
covariance.
traduisent la dispersion des abscisses
et des ordonnées. Pour aller plus loin dans la description, il faut calculer
la
covariance.
Cette définition étend celle de la
variance,
dans la mesure où
![]() . La
covariance
est symétrique (
. La
covariance
est symétrique (
![]() ) et
bilinéaire : si
) et
bilinéaire : si ![]() et
et ![]() sont deux
échantillons
de taille
sont deux
échantillons
de taille ![]() ,
,
![]() et
et ![]() deux réels et
deux réels et
![]() , alors :
, alors :
Comme conséquence de la bilinéarité, on a :
Pour le calcul pratique, on utilise la formule suivante :
La covariance est la moyenne des produits moins le produit des moyennes.
Démonstration : Il suffit de développer les produits :
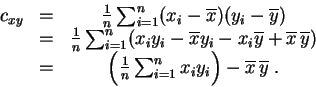
La covariance se compare au produit des écarts-types par l'inégalité de Cauchy-Schwarz.
Démonstration : Choisissons une constante ![]() quelconque et calculons la
variance
de
quelconque et calculons la
variance
de
![]() :
:
Cette quantité est positive ou nulle pour tout ![]() . Donc le discriminant
de l'expression, vue comme un trinôme en
. Donc le discriminant
de l'expression, vue comme un trinôme en ![]() , est nécessairemement
négatif. Il vaut :
, est nécessairemement
négatif. Il vaut :
d'où le résultat. Remarquons que le discriminant est nul si et seulement
si
![]() peut s'annuler, c'est-à-dire s'il existe
peut s'annuler, c'est-à-dire s'il existe ![]() tel que
tel que
![]() soit constant. Donc l'inégalité 3.1 ne peut
être une égalité que s'il existe une relation affine entre
soit constant. Donc l'inégalité 3.1 ne peut
être une égalité que s'il existe une relation affine entre ![]() et
et ![]() .
.![]()
Au vu de l'inégalité 3.1, il est naturel de diviser la covariance par le produit des écarts-types, pour définir le coefficient de corrélation.
Quels que soient l'unité et les ordres de grandeur de ![]() et
et ![]() , le
coefficient de corrélation
est un nombre sans unité, compris entre -1 et 1. Il traduit la plus ou
moins grande dépendance linéaire
de
, le
coefficient de corrélation
est un nombre sans unité, compris entre -1 et 1. Il traduit la plus ou
moins grande dépendance linéaire
de ![]() et
et ![]() ou, géométriquement, le plus ou moins grand aplatissement
ne pouvait être une égalité que si
ou, géométriquement, le plus ou moins grand aplatissement
ne pouvait être une égalité que si ![]() est constant ou si
est constant ou si ![]() est de
la forme
est de
la forme ![]() . Si
. Si ![]() est positif, le
coefficient de corrélation
de
est positif, le
coefficient de corrélation
de ![]() avec
avec ![]() est égal à +1, il est égal à -1 si
est égal à +1, il est égal à -1 si ![]() est
négatif. Un
coefficient de corrélation
nul ou proche de 0
signifie qu'il n'y a pas de relation linéaire entre les
caractères.
Mais il n'entraîne aucune notion
d'indépendance
plus générale.
Considérons par exemple les deux échantillons :
est
négatif. Un
coefficient de corrélation
nul ou proche de 0
signifie qu'il n'y a pas de relation linéaire entre les
caractères.
Mais il n'entraîne aucune notion
d'indépendance
plus générale.
Considérons par exemple les deux échantillons :
Quand le coefficient de corrélation est proche de 1 ou -1, les caractères sont dits "fortement corrélés". Il faut prendre garde à la confusion fréquente entre corrélation et causalité. Que deux phénomènes soient corrélés n'implique en aucune façon que l'un soit cause de l'autre. Très souvent, une forte corrélation indique que les deux caractères dépendent d'un troisième, qui n'a pas été mesuré. Ce troisième caractère est appelé "facteur de confusion". Qu'il existe une corrélation forte entre le rendement des impôts en Angleterre et la criminalité au Japon, indique que les deux sont liés à l'augmentation globale de la population. Le prix du blé et la population des rongeurs sont négativement corrélés car les deux dépendent du niveau de la récolte de blé. Il arrive qu'une forte corrélation traduise bien une vraie causalité, comme entre le nombre de cigarettes fumées par jour et l'apparition d'un cancer du poumon. Mais ce n'est pas la statistique qui démontre la causalité, elle permet seulement de la détecter. L'influence de la consommation de tabac sur l'apparition d'un cancer n'est scientifiquement démontrée que dans la mesure où on a pu analyser les mécanismes physiologiques et biochimiques qui font que les goudrons et la nicotine induisent des erreurs dans la reproduction du code génétique des cellules.